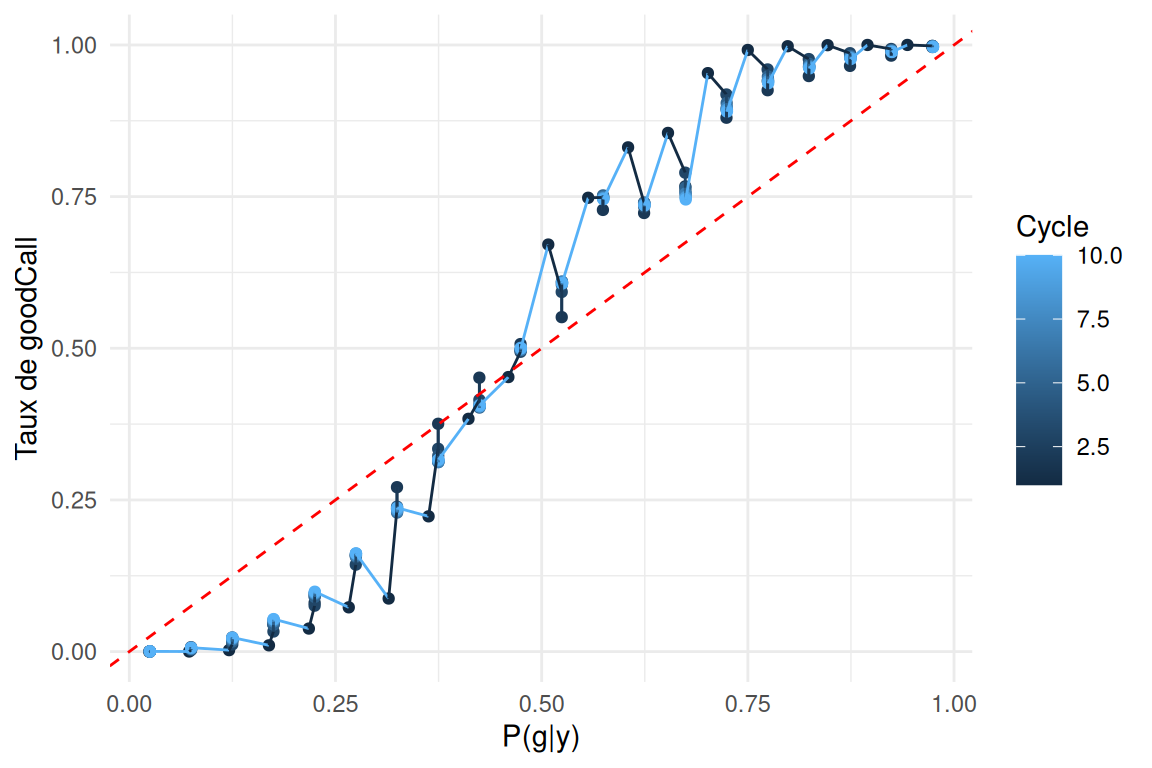
Réunion 20/03/26
Test et Plots
tests effectués sur SimuPop \(\epsilon = 10\%\)
distribution de densitée
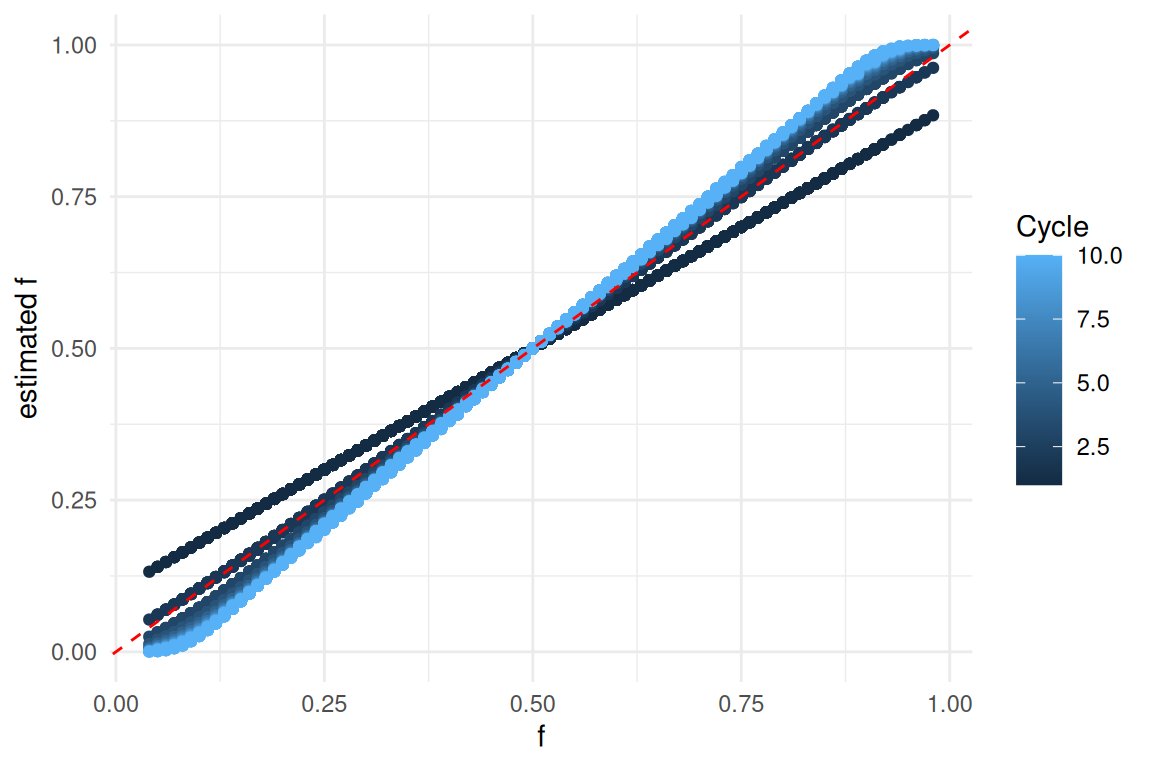
Test et Plots
tests effectués sur SimuPop \(\epsilon = 10\%\)
qualité d’estimation
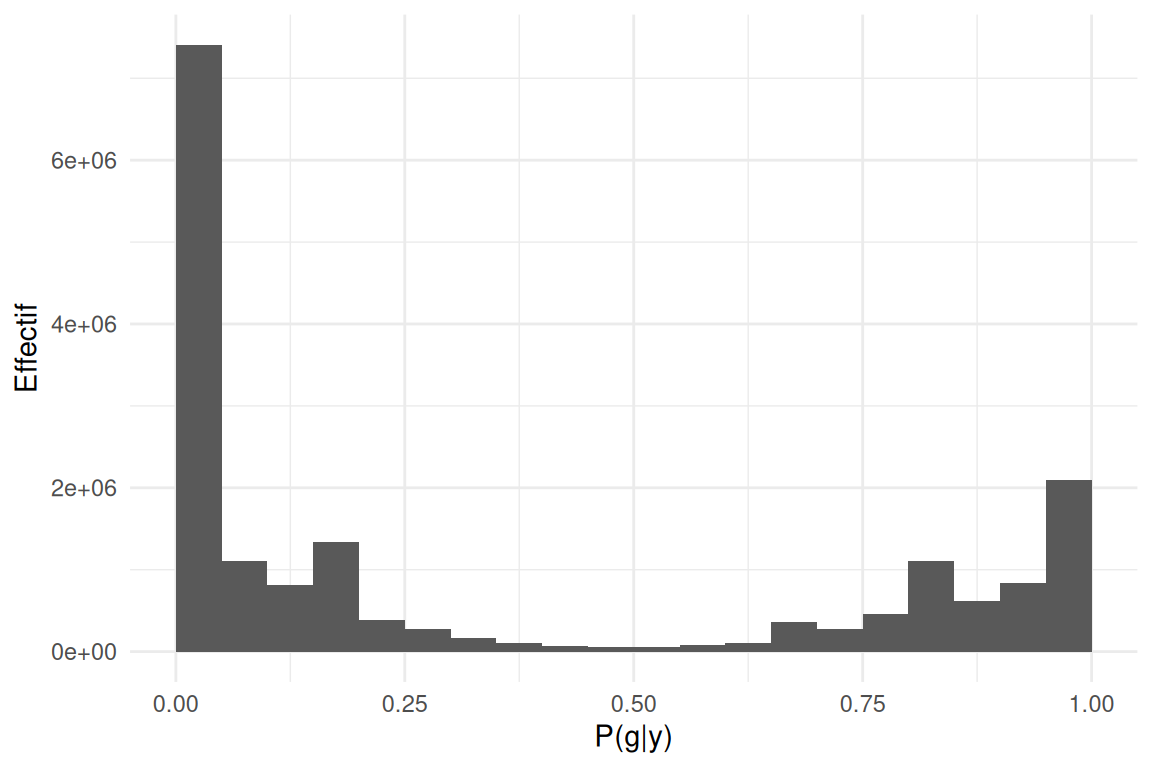
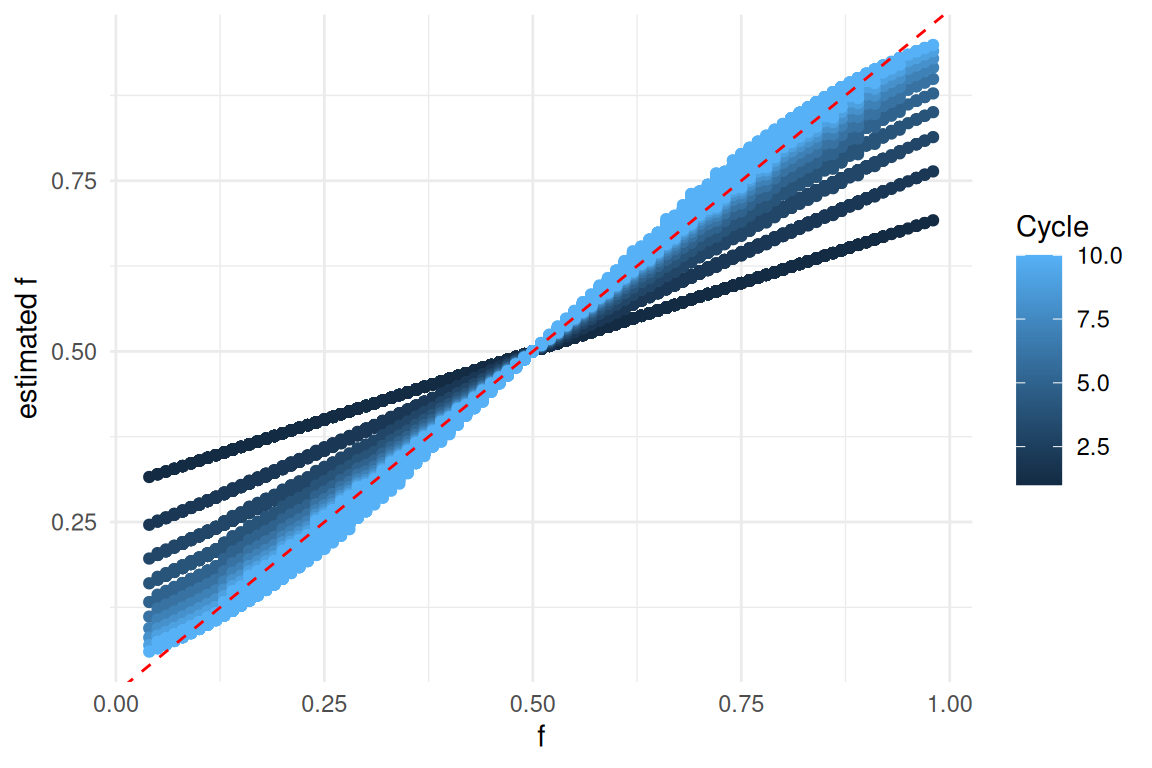
Test et Plots
tests effectués sur SimuPop \(\epsilon = 30\%\)
Estimation de la “AAF” en fonction de la “AAF” réelle au cours des Cycles
Test et Plots
tests effectués sur SimuPop $= 30% $
distribution de densitée
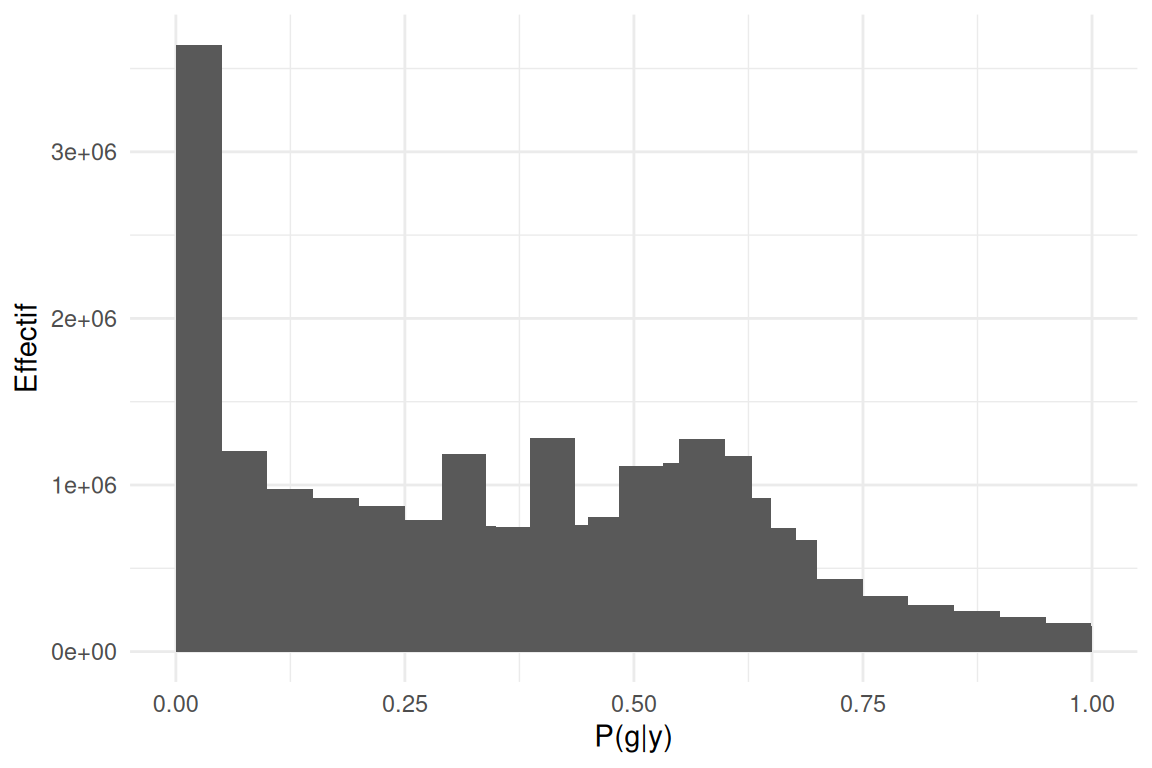
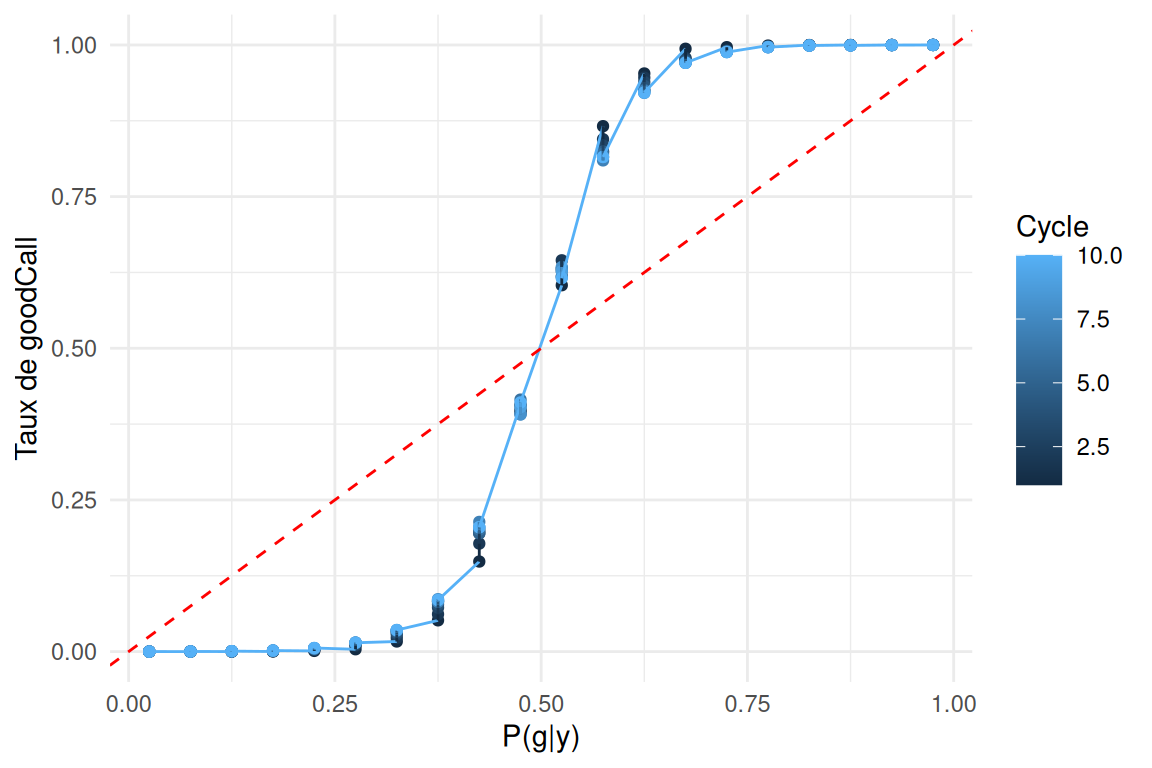
Test et Plots
tests effectués sur SimuPop \(\epsilon = 30\%\)
qualité d’estimation